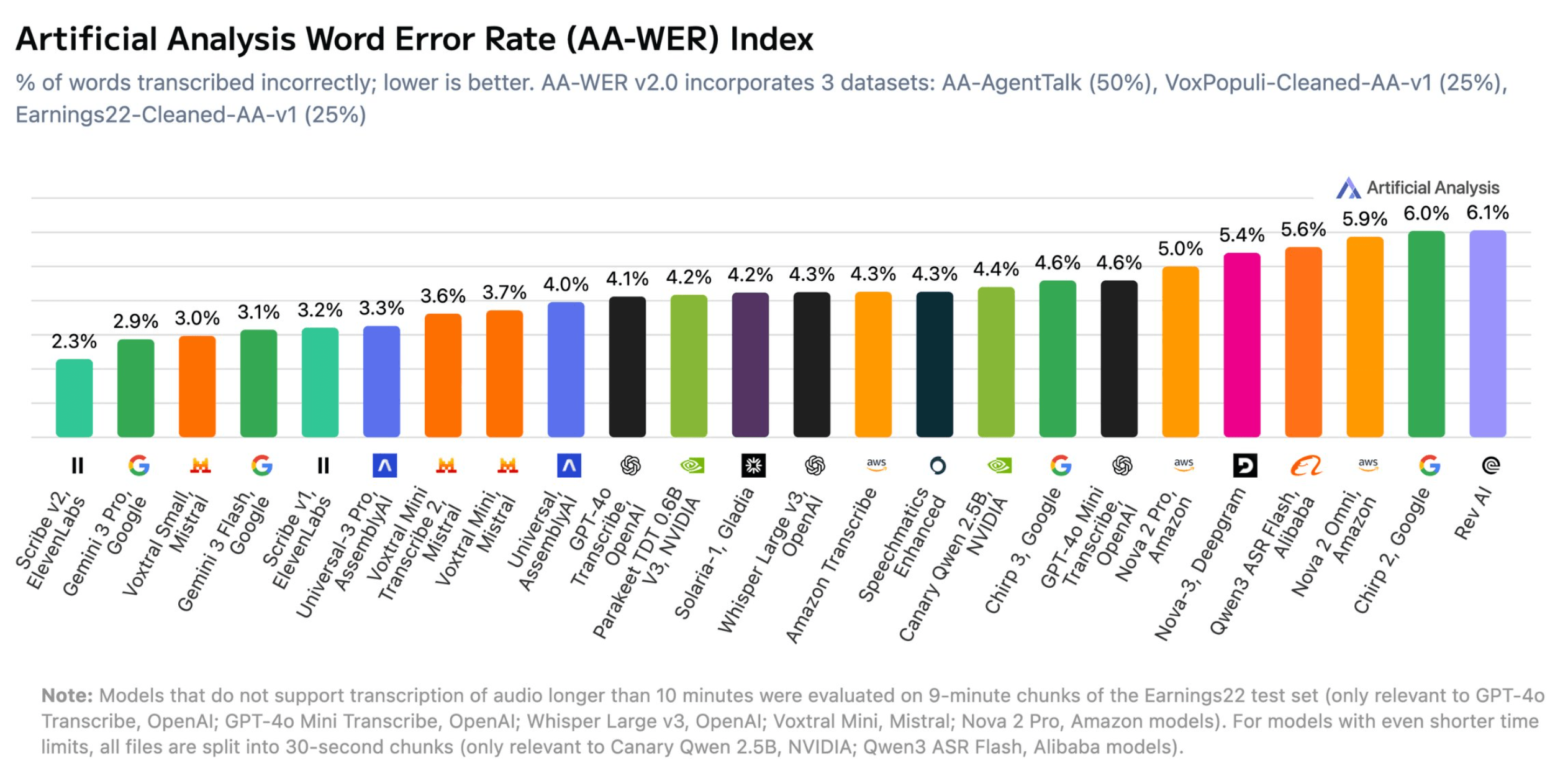
Artificial Analysis hat Version 2.0 seines Speech-to-Text-Benchmarks AA-WER veröffentlicht, der die Genauigkeit von Spracherkennungsmodellen misst. Im Gesamtranking führt Scribe v2 von ElevenLabs mit einer Wortfehlerrate von nur 2,3 Prozent. Auf den Plätzen zwei und drei folgen Googles Gemini 3 Pro (2,9 %) und Voxtral Small von Mistral (3,0 %). Auch Gemini 3 Flash von Google (3,1 %) und Scribe v1 von ElevenLabs (3,2 %) schneiden gut ab. Im Mittelfeld landen unter anderem OpenAIs GPT-4o Transcribe (4,0 %) und Whisper Large v3 (4,2 %). Am unteren Ende liegen Modelle wie Qwen3 ASR Flash von Alibaba (5,9 %), Amazons Nova 2 Omni (6,0 %) und Rev AI (6,1 %).
ElevenLabs Scribe v2 führt das Gesamtranking des AA-WER v2.0 Benchmarks mit der niedrigsten Wortfehlerrate an, gefolgt von Google Gemini 3 Pro und Mistral Voxtral Small. | Bild: Artificial Analysis
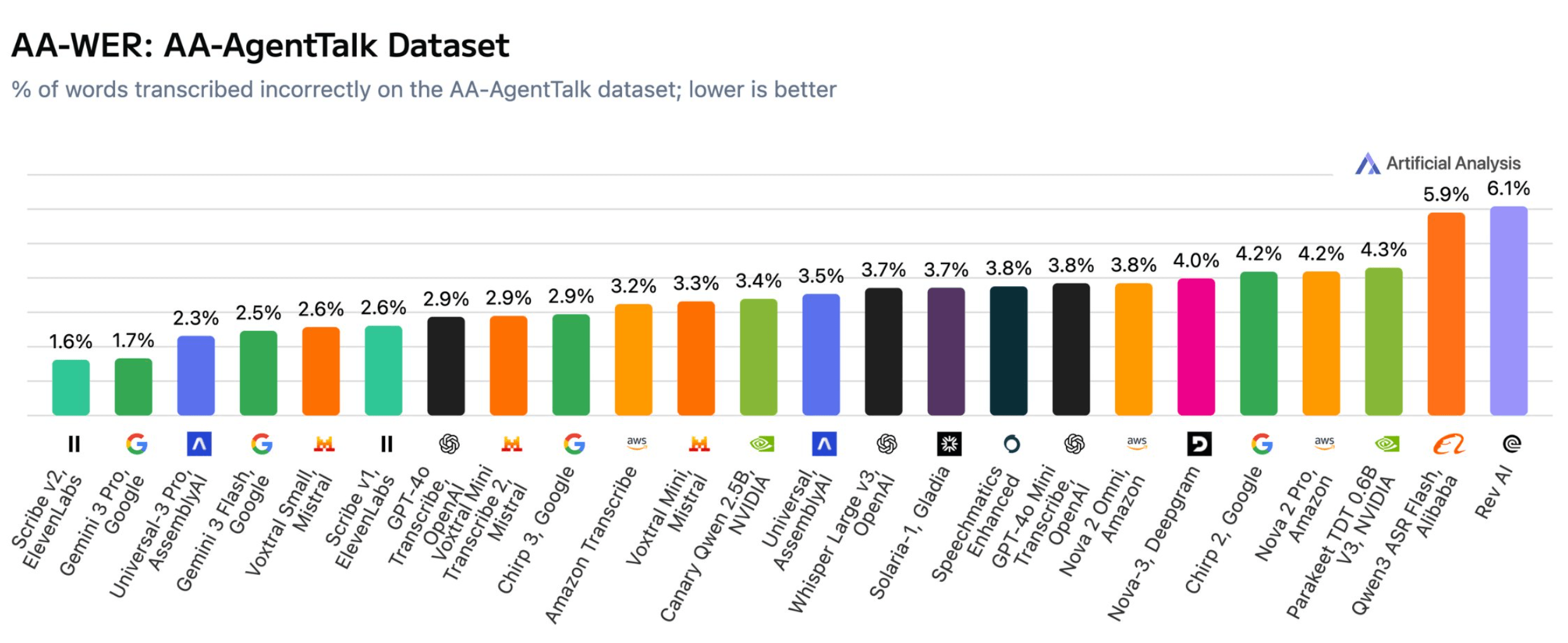
Im separaten Test mit Sprache, die speziell an Sprachassistenten gerichtet ist, bestätigt sich das Bild: Scribe v2 (1,6 %) und Gemini 3 Pro (1,7 %) liegen klar vorn. Universal-3 Pro von AssemblyAI folgt mit 2,3 Prozent auf Platz drei.
Auch im AA-AgentTalk-Test für Sprache an Sprachassistenten dominieren Scribe v2 von ElevenLabs und Gemini 3 Pro von Google mit den geringsten Fehlerquoten. | Bild: Artificial Analysis
Angebliche KI-Agenten-Zivilisation "Moltbook" ist nur aufgeblähter Bot-Traffic
Auf der gehypten KI-Agenten-Plattform Moltbook interagieren Millionen von KI-Agenten ohne menschliche Beteiligung. Eine Studie zeigt: Die Agenten posten, kommentieren und voten – lernen aber nicht voneinander. Hohle Interaktion ohne gegenseitigen Einfluss, ohne Gedächtnis, ohne soziale Strukturen.
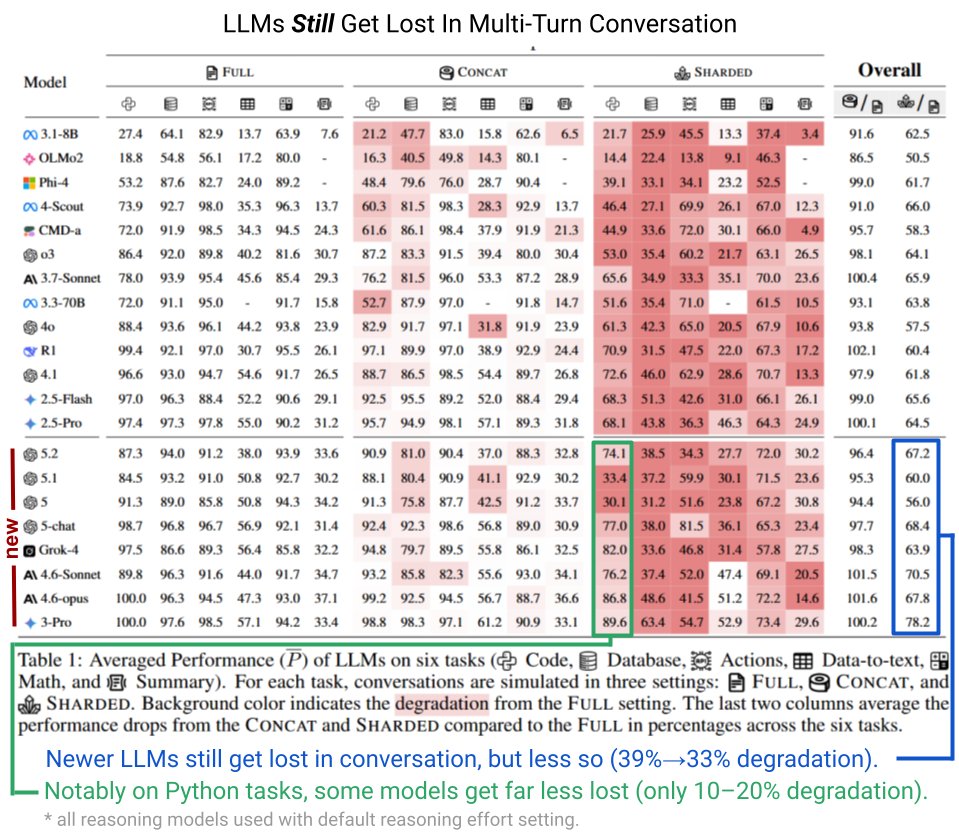
Auch die neue Generation großer Sprachmodelle (LLMs) ab GPT-5 hat nach wie vor Probleme, wenn Aufgaben über mehrere Gesprächsrunden verteilt werden. Forscher Philippe Laban und sein Team testeten aktuelle Modelle in sechs Aufgaben: Code, Datenbanken, Aktionen, Daten-zu-Text, Mathematik und Zusammenfassungen. Ergebnis: Die Leistung sinkt deutlich, wenn Informationen über mehrere Nachrichten verteilt (sharded) statt in einer einzigen Anfrage (concat) gegeben werden.
Neuere Modelle schneiden zwar etwas besser ab – sie verlieren im Schnitt 33 statt zuvor 39 Prozent ihrer Leistung –, doch das Problem bleibt bestehen. Verbesserungen zeigten sich primär bei Python-Programmieraufgaben, wo einige Modelle nur noch 10 bis 20 Prozent Leistung einbüßten. Die Tests nutzten einfache, unkomplizierte Nutzersimulationen. Laban vermutet, dass der Verlust noch größer ausfallen könnte, wenn Nutzer etwa mitten im Gespräch ihre Meinung ändern.
OpenAI beweist Doppelmoral: Sam Altmans früherer Mitstreiter ist nun ein Dystopist
Angst erzeugt Aufmerksamkeit, und OpenAI weiß diesen Effekt regelmäßig zu nutzen. Doch vor Gericht will das Unternehmen einen KI-Experten als Untergangspropheten diskreditieren, dessen KI-Warnungen der eigene CEO Sam Altman jahrelang selbst verbreitet hat, als sie noch der eigenen Sache dienten.
OpenAI hat der kanadischen Regierung in einem Schreiben an KI-Minister Evan Solomon zugesagt, seine Sicherheitsprotokolle zu verschärfen. Anlass ist eine tödliche Schießerei an einer Schule in Tumbler Ridge, British Columbia, bei der acht Menschen starben. Der Verdächtige, Jesse Van Rootselaar, hatte zuvor mit ChatGPT interagiert. OpenAI-Angestellte stuften die Interaktionen als mögliche Warnung vor realer Gewalt ein. Das Unternehmen sperrte das Konto, informierte aber nicht die Polizei.
Laut Wall Street Journal will OpenAI nun flexiblere Kriterien für die Weitergabe von Kontodaten an Behörden einführen, direkte Kontakte zur kanadischen Polizei aufbauen und seine Systeme zur Umgehungserkennung verbessern. OpenAI-Vizepräsidentin Ann O'Leary sagte, man hätte das Konto nach den neuen Regeln gemeldet. Kanadas Justizminister Sean Fraser drohte mit neuen KI-Regulierungen, sollte OpenAI nicht schnell handeln.
KI-Daten: Aktuelles Sprachmodell-Training verschenkt große Teile des Internets
Große Sprachmodelle lernen aus Webdaten. Doch welche Seiten im Trainingsdatensatz landen, hängt stark vom HTML-Extraktor ab. Forscher bei Apple, Stanford und der University of Washington zeigen, dass drei gängige Werkzeuge überraschend unterschiedliche Teile des Webs erschließen: Nur 39 Prozent der Seiten überleben bei mehr als einem Extraktor.